
python 中文编码乱码问题原理分析及解决思路
1. 为了处理英文字符,产生了ASCII码。
2. 为了处理中文字符,产生了GB2312。
3. 为了处理各国字符,产生了Unicode。
4. 为了提高Unicode存储和传输性能,产生了UTF-8,它是Unicode的一种实现形式。
Python2中默认的字符编码是ASCII码,也就是说Python在处理数据时,只要数据没有指定它的编码类型,Python默认将其当做ASCII码来进行处理。这个问题最直接的表现在当我们编写的python文件中包含有中文字符时,在运行时会提示出错
# -*- coding: utf-8 -*- |
这样,Python在处理这个脚本时,会用UTF-8的编码去处理整个脚本,就能够正确的解析中文字符了。
decode()方法将其他编码字符转化为Unicode编码字符。
encode()方法将Unicode编码字符转化为其他编码字符。

一个Tips:decode()方法与在字符串前加u的方法实现的效果相同比如u’小明’
网页中已经声明了它是一个gb2312的字符编码,而我的系统中默认的字符编码为UTF-8显然,我必须要将title转换为UTF-8的字符。
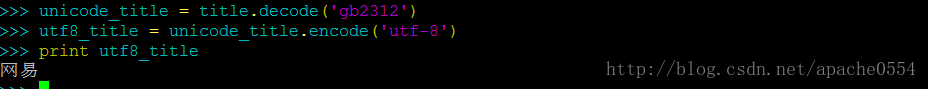
python中gbk转utf8_Python 处理GBK编码转UTF-8读写乱码问题
老套路,首先获取网页源代码
#-*- coding:utf-8 -*-
import requests
url = 'http://search.51job.com/jobsearch/search_result.php?'
page_req = requests.get(url)
page = page_req.text.encode('utf-8')
print page
结果,中文乱码:
浏览器查看,前程无忧源代码,是GBK编码,好吧,转GBK
非法字符,好吧,高级点,我转GB18030
尼玛,又是一种奇怪的字符,继续整,找网页帖子,大概是说先解码成GBK再转UTF_8 把 page = page_req.text.decode('gbk').encode('utf-8') 改成这样
问题是,Python默认字符是ASCII的,decode('GBK')或decode('GB18030')都不成,非法啊。
后来,去stackoverflow看了看,找到了答案,先编码成iso-8859-1在转GBK,问题完美解决
page = page_req.text.encode('iso-8859-1').decode('gbk')
————————————————
版权声明:本文为CSDN博主「weixin_40009207」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_40009207/article/details/112032503